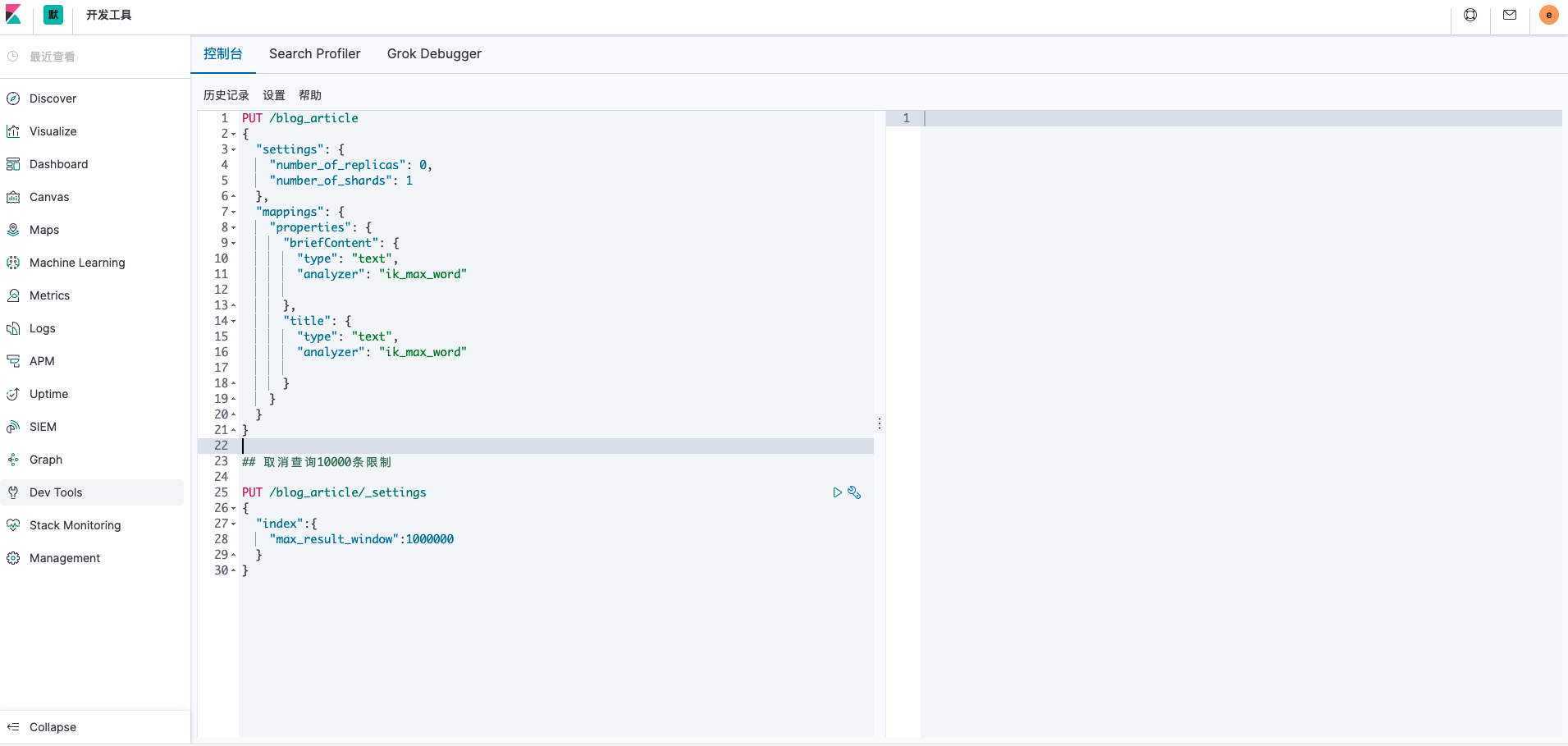
在kibana控制台中或通过API创建文档设置中文分词,配置等,例如:
PUT /blog_article
{
"settings": {
"number_of_replicas": 0,
"number_of_shards": 1
},
"mappings": {
"properties": {
"briefContent": {
"type": "text",
"analyzer": "ik_max_word"
},
"title": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
## 取消查询10000条限制
PUT /blog_article/_settings
{
"index":{
"max_result_window":1000000
}
}
依赖
<properties>
<elasticsearch.version>7.6.2</elasticsearch.version>
</properties>
<dependencies>
...
<!-- SpringBoot集成elasticsearch -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
</dependencies>
配置文件
application.yml
spring:
elasticsearch:
rest:
uris: http://127.0.0.1:9200
username: xxxx
password: xxxx
read-timeout: 30s
connection-timeout: 30s
启动类
@SpringBootApplication
public class Application
{
public static void main(String[] args)
{
//在启动类中加入,解决异常: availableProcessors is already set to [4], rejecting [4]
System.setProperty("es.set.netty.runtime.available.processors", "false");
}
}
配置类
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.ObjectProvider;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.autoconfigure.elasticsearch.RestClientBuilderCustomizer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.elasticsearch.repository.config.EnableElasticsearchRepositories;
import java.util.concurrent.TimeUnit;
@Configuration
//扫描Repository
@EnableElasticsearchRepositories(basePackages = "com.xx.xx.repository.*")
public class ElasticSearchConfig {
@Autowired
private RestClientBuilder restClientBuilder;
/**
* KeepAlive 默认-1 没有限制 , 服务超出时间会主动断开,配置客户端的时间短于服务器时间
* org.springframework.dao.DataAccessResourceFailureException: Connection reset by peer; nested exception is java.lang.RuntimeException: Connection reset by peer
*
* @return void
* @date 2021/08/27 15:03
*/
@Bean
public RestHighLevelClient elasticsearchRestHighLevelClient(ObjectProvider<RestClientBuilderCustomizer> builderCustomizers) {
restClientBuilder.setHttpClientConfigCallback((httpClientBuilder) -> {
builderCustomizers.orderedStream().forEach((customizer) -> customizer.customize(httpClientBuilder));
//DefaultConnectionKeepAliveStrategy KeepAlive 默认-1 没有限制
httpClientBuilder.setKeepAliveStrategy((response, context) -> TimeUnit.MINUTES.toMillis(3));
return httpClientBuilder;
});
return new RestHighLevelClient(restClientBuilder);
}
}
实体类
// 添加注解
@org.springframework.data.elasticsearch.annotations.Document(indexName = "blog_article")
public class ArticleInfo {
....
}
Repository 配置(可选)
在repository目录中创建XXXElasticsearchRepository 类
import com.xxx.domain.ArticleInfo;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
public interface ArticleElasticsearchRepository extends ElasticsearchRepository<ArticleInfo,String>{
}
Service 使用
- 使用Repository
@Autowired private ArticleElasticsearchRepository articleElasticsearchRepository;
- 使用ElasticsearchRestTemplate
@Autowired private ElasticsearchRestTemplate elasticsearchRestTemplate; // 保存 elasticsearchRestTemplate.save(articleInfo); // 批量保存 List<ArticleInfo> list = xx; elasticsearchRestTemplate.save(list); //删除 elasticsearchRestTemplate.delete(obj); // 查询 //创建查询构建器 NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder(); //排序 Sort sort = Sort.by("字段名").descending(); // 分页 Pageable pageable = PageRequest.of(pageNum, pageSize, sort); //完全匹配,.keywork 为ES自动生成 queryBuilder.withQuery(QueryBuilders.matchQuery("name.keywork", name)); //模糊匹配 queryBuilder.withQuery(QueryBuilders.matchQuery("name", name)); //分页查询 queryBuilder.withPageable(pageable); NativeSearchQuery query = queryBuilder.build(); //取消10000条限制 query.setTrackTotalHits(true); SearchHits<ArticleInfo> searchHits = elasticsearchRestTemplate.search(query, ArticleInfo.class); List<ArticleInfo> list = searchHits.getTotalHits();
Elasticsearch条件查询
通过ElasticsearchTemplate模板结合Query实现保存与查找。
匹配所有文档的查询。
matchAllQuery()
为提供的字段名和文本创建类型为“BOOLEAN”的匹配查询。(解释过来就是单个匹配,可以模糊匹配)
matchQuery(String name, Object text) //name 字段值 ,text 查询文本(不支持通配符)
为提供的字段名和文本创建一个通用查询。
commonTermsQuery(String name, Object text)
为提供的字段名和文本创建类型为“BOOLEAN”的匹配查询。
multiMatchQuery(Object text, String... fieldNames)
为提供的字段名和文本创建一个文本查询,并输入“短句”。
matchPhraseQuery(String name, Object text)
为提供的字段名和文本创建一个与类型“PHRASE_PREFIX”匹配的查询。
matchPhrasePrefixQuery(String name, Object text)
匹配包含术语的文档的查询。
termQuery(String name, Object value)
使用模糊查询匹配文档的查询
fuzzyQuery(String name, Object value)
与包含指定前缀的术语的文档相匹配的查询。
prefixQuery(String name, String prefix)
在一定范围内匹配文档的查询。
rangeQuery(String name)
实现通配符搜索查询。支持的通配符是*,它匹配任何字符序列(包括空字符),而?它匹配任何单个字符。注意,这个查询可能很慢,因为它需要遍历许多项。为了防止异常缓慢的通配符查询,通配符项不应该以一个通配符*或?开头。
wildcardQuery(String name, String query) //query 通配符查询字符串
将包含术语的文档与指定的正则表达式匹配的查询
regexpQuery(String name, String regexp) //regexp的正则表达式
解析查询字符串并运行它的查询。有两种模式。第一,当没有字段添加(使用QueryStringQueryBuilder.field(字符串),将运行查询一次,非前缀字段将使用QueryStringQueryBuilder.defaultField(字符串)。第二,当一个或多个字段添加(使用QueryStringQueryBuilder.field(String)),将运行提供的解析查询字段,并结合使用DisMax或普通的布尔查询(参见QueryStringQueryBuilder.useDisMax(布尔))。
queryStringQuery(String queryString)
类似于query_string查询的查询,但不会为任何奇怪的字符串语法抛出异常。
simpleQueryStringQuery(String queryString)
可以使用BoostingQuery类来有效地降级与给定查询匹配的结果。
boostingQuery()
匹配与其他查询的布尔组合匹配的文档的查询
boolQuery()
创建一个可用于实现MultiTermQueryBuilder的子查询的SpanQueryBuilder。
spanMultiTermQueryBuilder(MultiTermQueryBuilder multiTermQueryBuilder)
允许定义自定义得分函数的查询。
functionScoreQuery(QueryBuilder queryBuilder, ScoreFunctionBuilder function)
更像这样的查询,查找“like”提供的文档,例如提供的MoreLikeThisQueryBuilder.likeText(String),它是针对查询所构造的字段进行检查的
moreLikeThisQuery(String... fields)
构造一个新的非计分子查询,包含子类型和要在子文档上运行的查询。这个查询的结果是这些子文档匹配的父文档。
hasChildQuery(String type, QueryBuilder query)
构造一个新的非评分父查询,父类型和在父文档上运行的查询。这个查询的结果是父文档匹配的子文档。
hasParentQuery(String type, QueryBuilder query)
基于对其中任何一个项进行匹配的若干项的字段文件
termsQuery(String name, String... values)
一个查询构建器,它允许构建给定JSON字符串或二进制数据作为输入的查询。当您希望使用Java Builder API,但仍然需要将JSON查询字符串与其他查询构建器结合时,这是非常有用的。
wrapperQuery(String source)
上述静态方法只是为了方便创建QueryBuilder系列对象。
条件查询
我们调用QueryBuilders 的静态方法创建完具体的QueryBuilder对象之后,传入.withQuery(QueryBuilder)方法就可以实现的自定义查询。
1.完全匹配
MatchQueryBuilder queryBuilder = QueryBuilders.matchQuery("字段名", "查询文本");2.短语匹配
MoreLikeThisQueryBuilder queryBuilder = QueryBuilders
.moreLikeThisQuery("name")// 要匹配的字段, 不填默认_all
.like("西游")// 匹配的文本
.minTermFreq(1);// 文本最少出现的次数(默认是2,我们设为1)我们再从源码去看其它方法
添加一些文本以查找“类似”的文档
addLikeText(String... likeTexts)
查找类似文档
like(Item... likeItems)
设置不从其中选择(比如我们调用.like("西游").unlike("西游记")这样会导致啥也查不到)
unlike(String... unlikeTexts)
添加一些文本以查找与此不同的文档
addUnlikeText(String... unlikeTexts)
设置将包含在任何生成查询中的查询条件的最大数量。默认25
maxQueryTerms(int maxQueryTerms)
设置单词被忽略的频率,默认5,小于将不会被发现
minDocFreq(int minDocFreq)
设置单词仍然出现的最大频率。单词出现更多的文档将被忽略。默认为无限
maxDocFreq(int maxDocFreq)
设置将被忽略的单词的最小单词长度,默认0
minWordLength(int minWordLength)
设置将被忽略的单词的最大单词长度,默认无限
maxWordLength(int maxWordLength)
设置停止词,匹配时会忽略停止词
stopWords(String... stopWords)
设置词语权重,默认是1
boostTerms(float boostTerms)
查询权重(默认1)
boost(float boost)
设置不从其中选择术语的文本(文档Item)
ignoreLike(String... likeText)4.组合查询
QueryBuilder queryBuilder = QueryBuilders.boolQuery()
.must(QueryBuilders.matchQuery("name", "西游")) //AND
.must(QueryBuilders.wildcardQuery("name", "西游?")) //Not
.should(QueryBuilders.matchQuery("name", "西游记")); //Or5.包裹查询
高于设定分数, 不计算相关性
QueryBuilder queryBuilder = QueryBuilders
.constantScoreQuery(QueryBuilders.matchQuery("name", "西游记"))
.boost(2.0f);
6.范围查询
查询id值在20-50之间的
QueryBuilder queryBuilder = QueryBuilders.rangeQuery("id")
.from("20")
.to("50")
.includeLower(true) // 包含上界
.includeUpper(true); // 包含下届
7.通配符查询
通配符查询, 支持 * 匹配任何字符序列, 包括空
避免* 开始, 会检索大量内容造成效率缓慢
单个字符用?
QueryBuilder queryBuilder = QueryBuilders.wildcardQuery("user", "ki*hy");
8.过滤查询
QueryBuilders.constantScoreQuery(FilterBuilders.termQuery("name", "kimchy")).boost(2.0f);

